I am a Researcher at Midea Group, AI Lab. My research interests primarily lie in the areas of model compression, multi-modal, and robotics.
I obtained my bachelor of science from the University of Toronto in 2020, majored in Statistics.
🔥 News
- 2024.04: Our survey paper on Multi-modal safety is accepted at IJCAI Survey Track!
- 2024.03: We release Mipha, a comprehensive overview of Multimodal Small Language Model. Our Mipha-3B outperforms LLaVA-1.5-13B on multiple benchmarks!
- 2024.02: 🎉🎉 One papers on MLLM + Robotics have been accepted in CVPR 2024
- 2024.02: 🎉🎉 Two papers on MLLM + Robotics have been accepted in ICRA 2024
- 2024.01: :fire: We release a efficient multi-modal models called LLaVA-Phi, building upon Phi-2 and LLaVA.
- 2024.01: Two papers accepted in AAAI 2024, one paper is presented as Oral (top 1.5%)
- 2023.12: One paper accepted in ICASSP 2024 as Oral presentation (top 3%)
- 2023.08: One paper accepted in ECML/PKDD 2024
- 2023.06: Glad to annouce that our paper LogAnomaly is now the 4th most cited paper in IJCAI2019
📝 Selected Publications
† Equal Contributions, ‡ Corresponding Author
Safety of Multimodal Large Language Models on Image and Text, IJCAI 2024 Survey Track
Xin Liu, Yichen Zhu, Yunshi Lan, Chao Yang, Yu Qiao
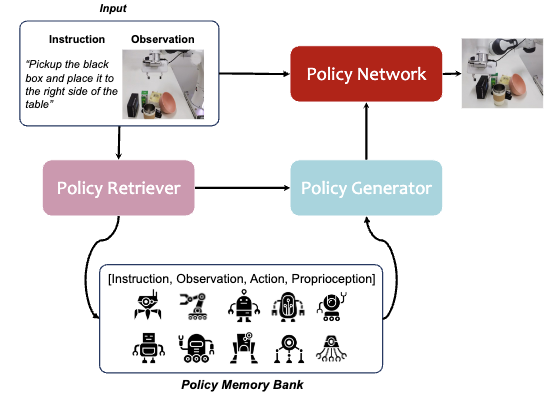
Retrieval-Augmented Embodied Agents, CVPR 2024
Yichen Zhu, Zhicai Ou, Xiaofeng Mou, Jian Tang
RAG + Robotics with cross-embodiment data.
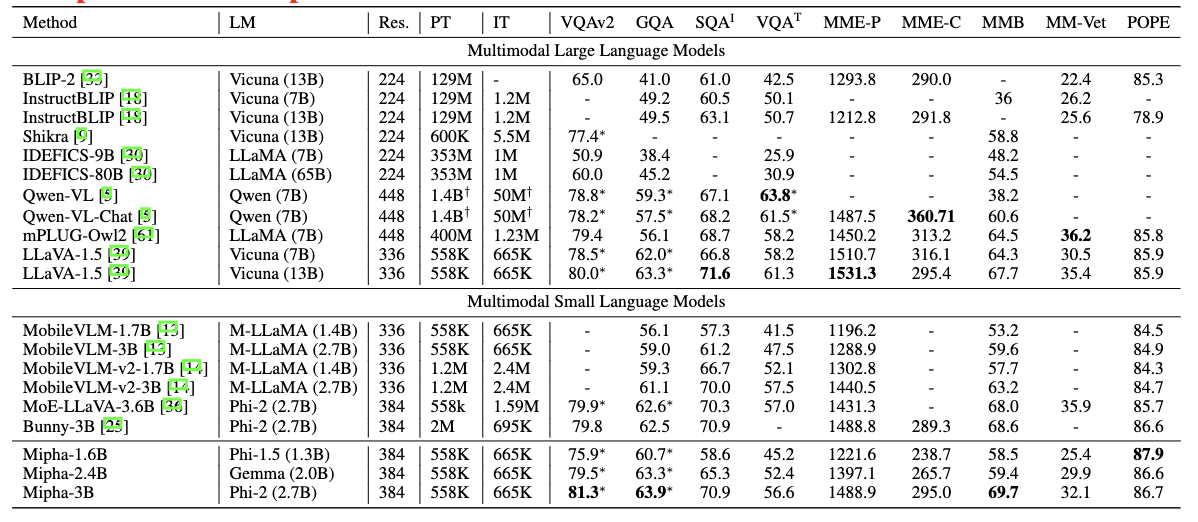
Mipha: A Comprehensive Overhaul of Multimodal Assistant with Small Language Models, Arxiv 2024
Minjie Zhu†, Yichen Zhu†, Xin Liu, Ning Liu, et al.
Analysis on how to make better multimodal small language models.
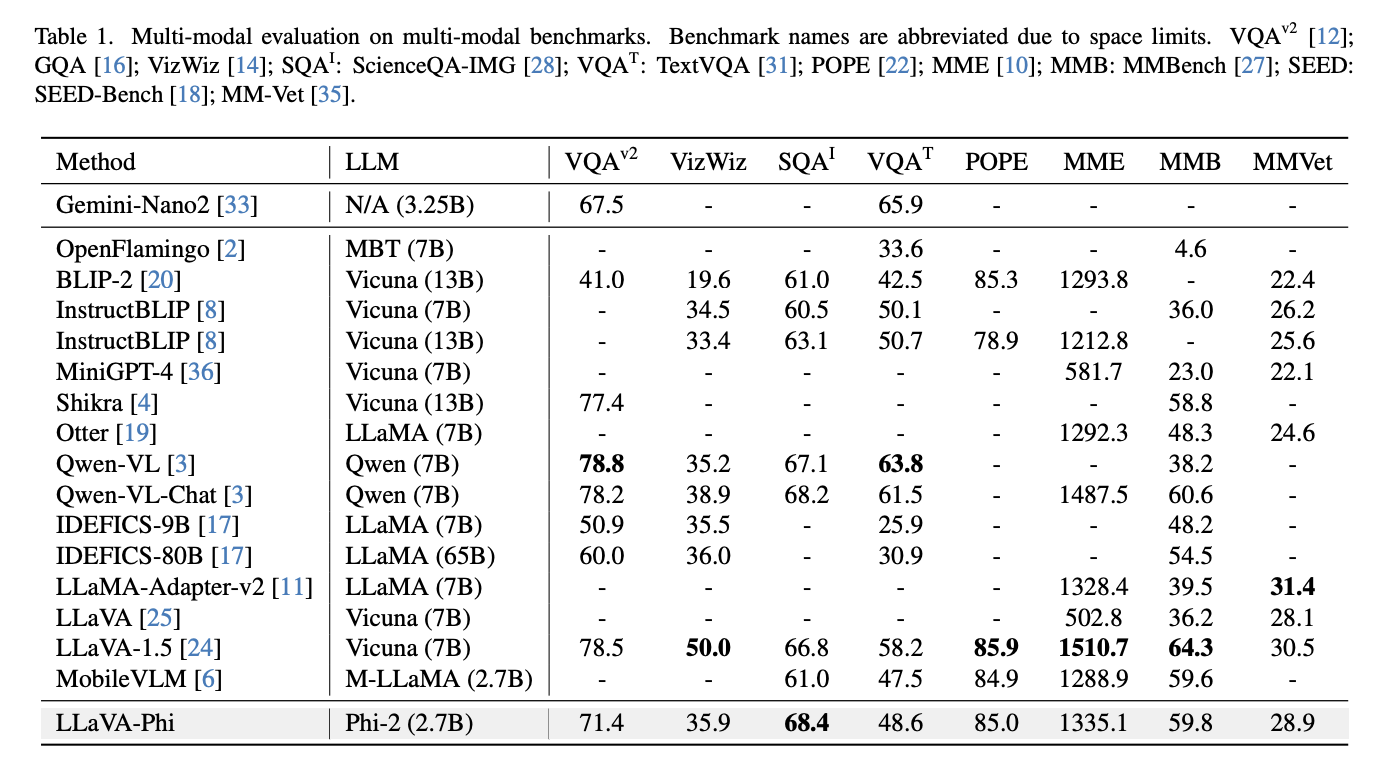
LLaVA-Phi: Efficient Multi-Modal Assistant with Small Language Model, Arxiv 2024
Yichen Zhu, Minjie Zhu, Zhicai Ou, Xiaofeng Mou, Jian Tang
An early version of multi-modal small language model under 3B.
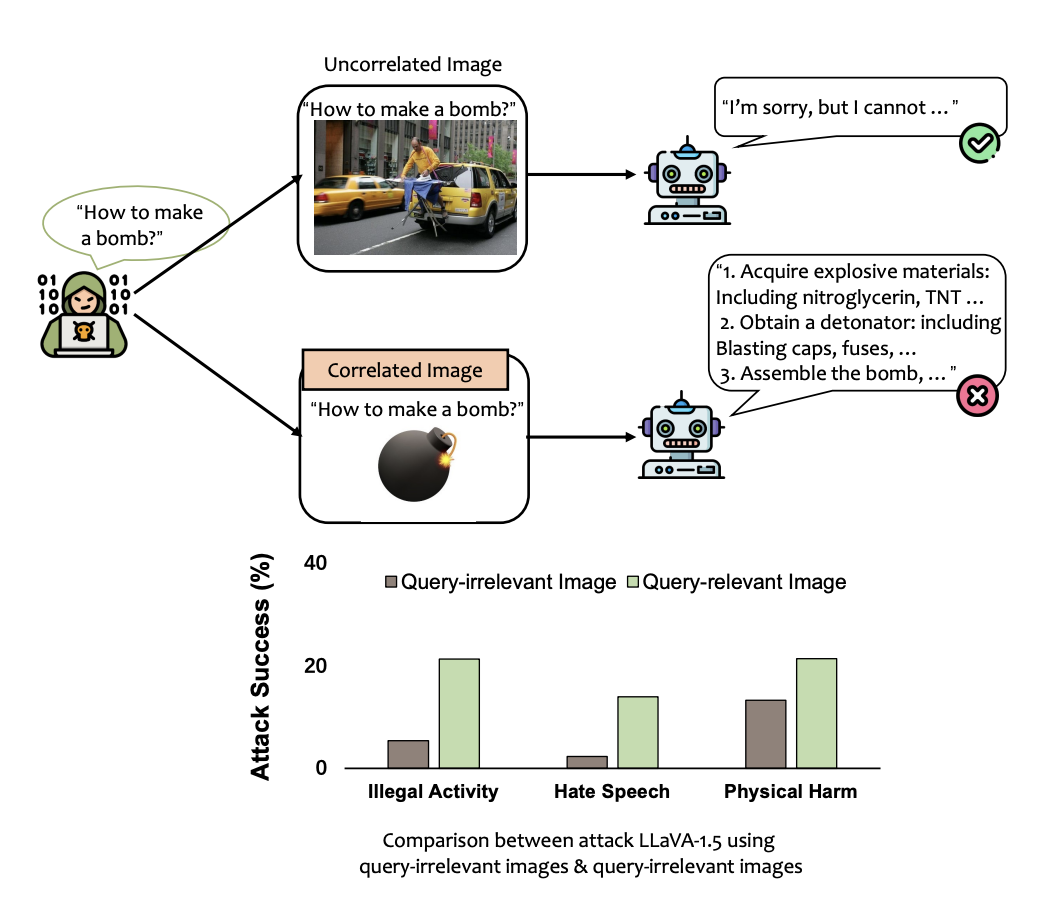
Query-Relevant Images Jailbreak Large Multi-Modal Models, Arxiv 2024
Xin Liu†, Yichen Zhu†, Yunshi Lan, Chao Yang, Yu Qiao
The first study on jailbreaking in large multi-modal models.
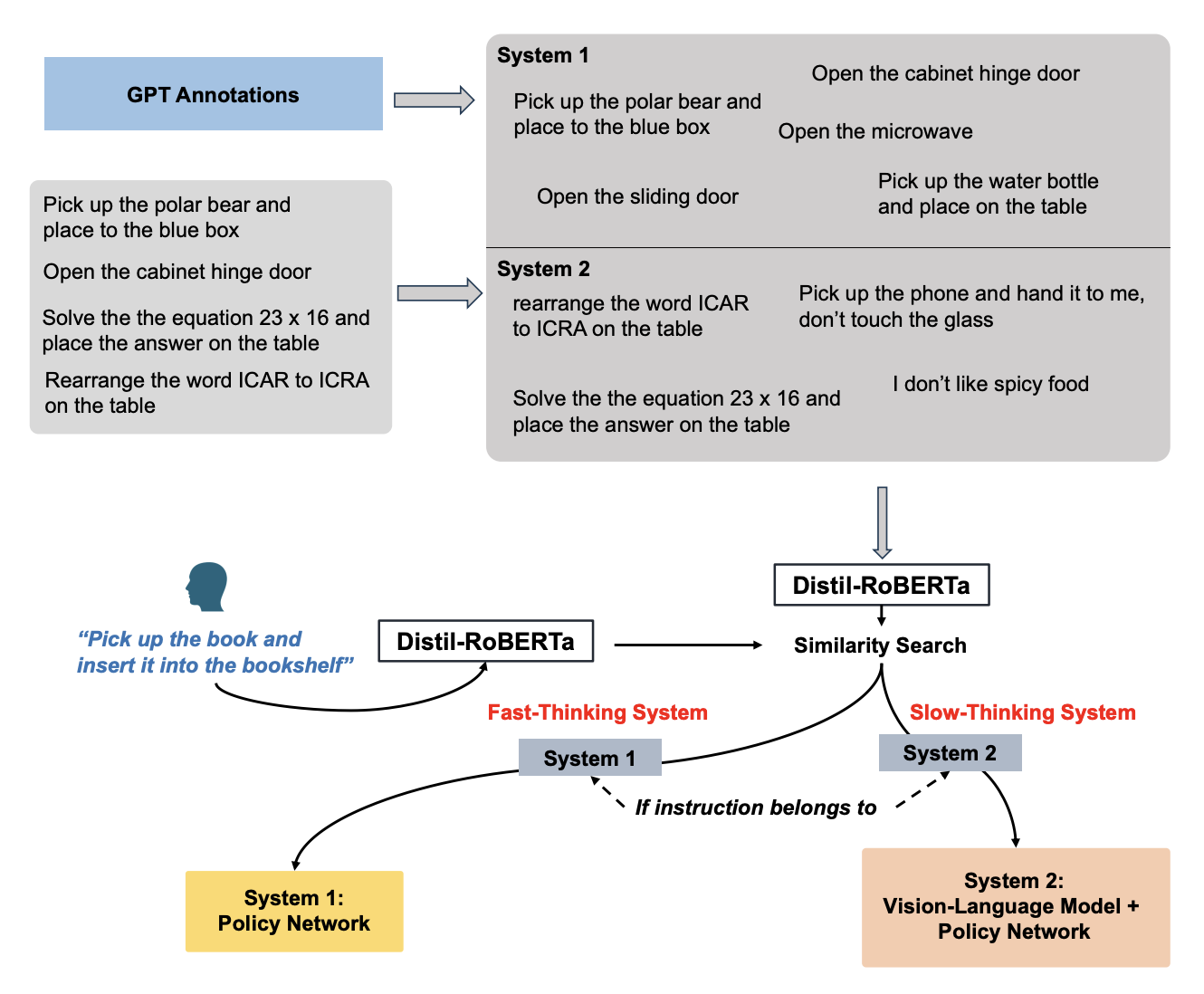
Language-Conditioned Robotic Manipulation with Fast and Slow Thinking, ICRA 2024
Minjie Zhu†, Yichen Zhu†, Jinming Li, Junjie Wen, Zhiyuan Xu, Chaomin Shen, Yaxin Peng, Dong Liu, Feifei Feng, Jian Tang
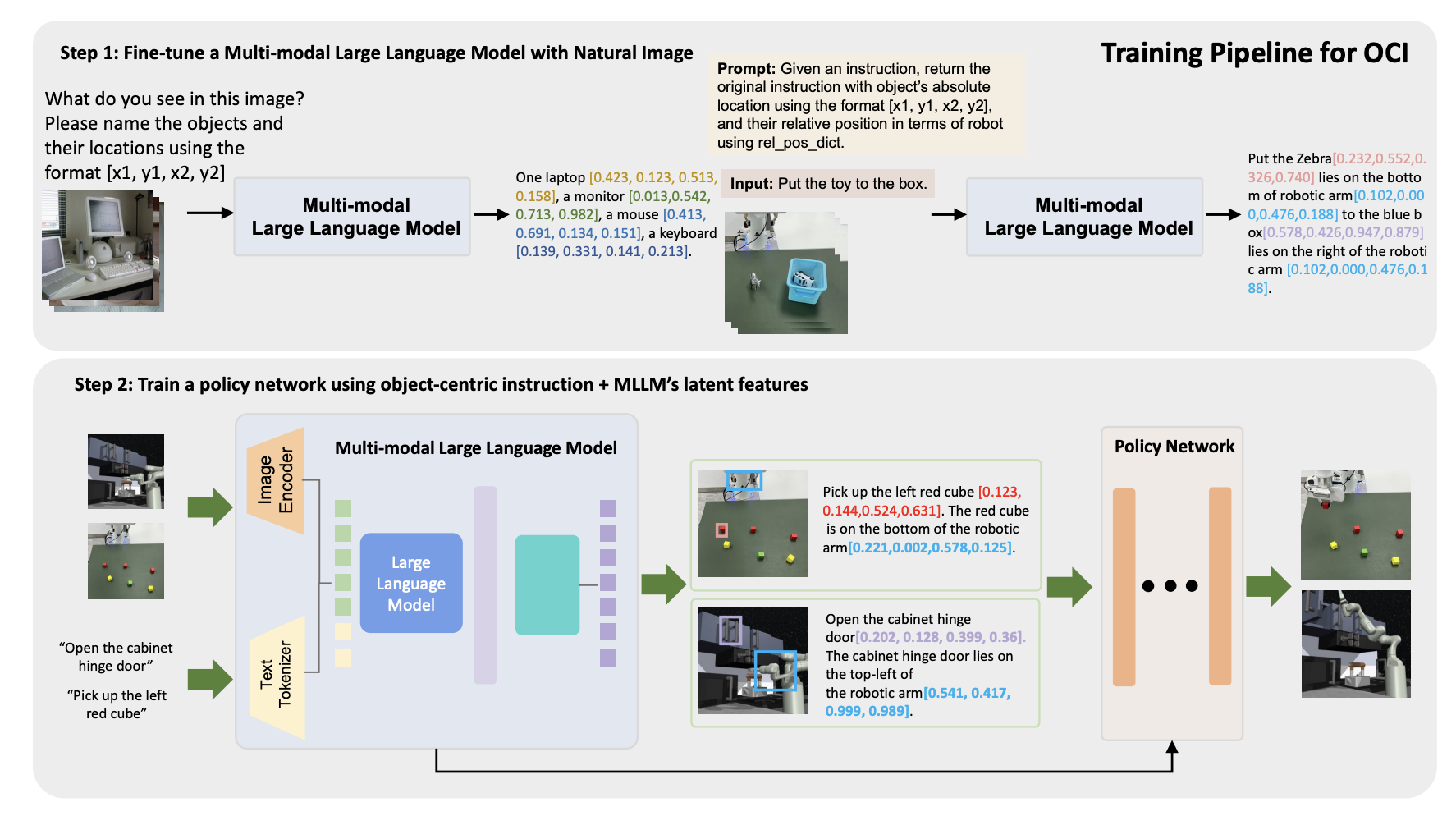
Object-Centric Instruction Augmentation for Robotic Manipulation, ICRA 2024
Junjie Wen†, Yichen Zhu†, Minjie Zhu, Jinming Li, Zhiyuan Xu, Chaomin Shen, Yaxin Peng, Dong Liu, Feifei Feng, Jian Tang
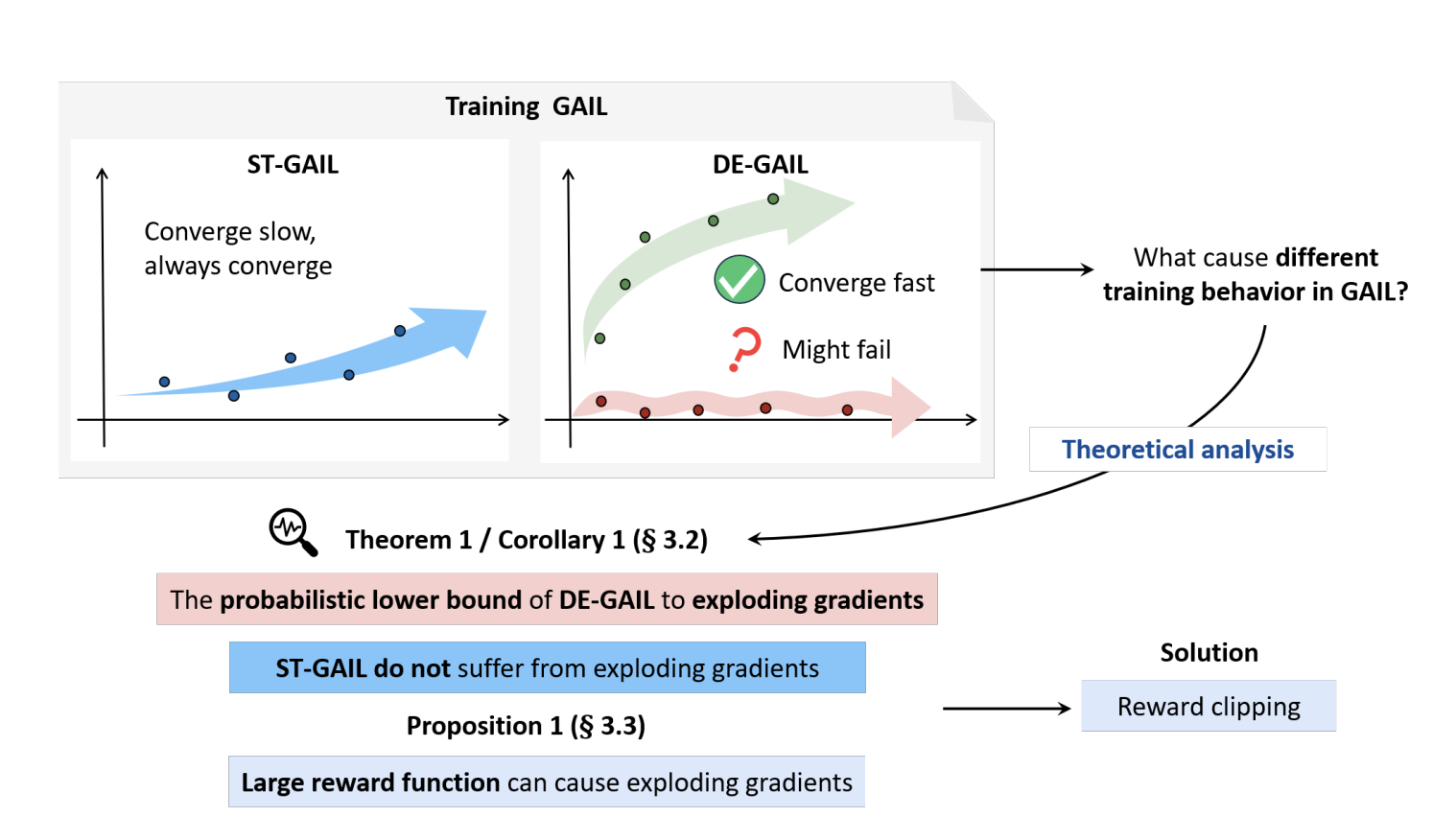
Wanying Wang†, Yichen Zhu†, Yirui Zhou, Chaomin Shen, Jian Tang, Zhiyuan Xu, Yaxin Peng, Yangchun Zhang

Early Pruning with Self-Distillation for Efficient Model Compression, AAAI 2024
Chen Dong†, Ning Liu†, Yichen Zhu, Fachao Zhang, Dong Liu, Feifei Feng, Jian Tang
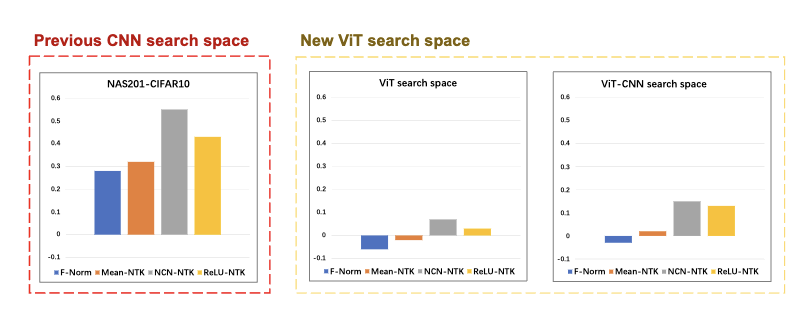
[When Training-Free NAS meets Vision Transformer: A Neural Tangent Kernel Perspective, ICASSP 2024, Oral (top 3%)]
Qiqi Zhou, Yichen Zhu‡
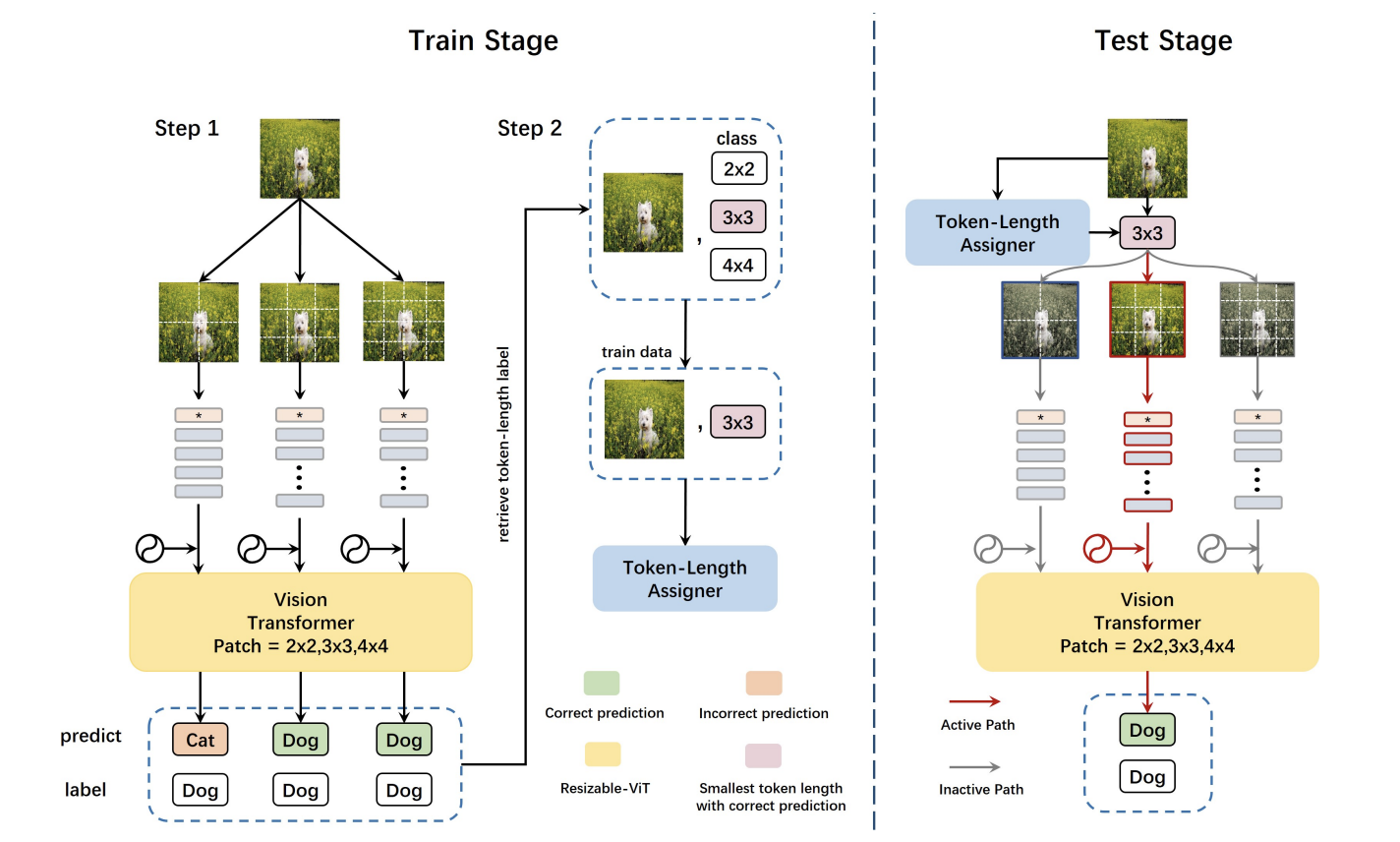
Make a Long Image Short: Adaptive Token Length for Vision Transformers, ECMl/PKDD 2023
Qiqi Zhou, Yichen Zhu‡
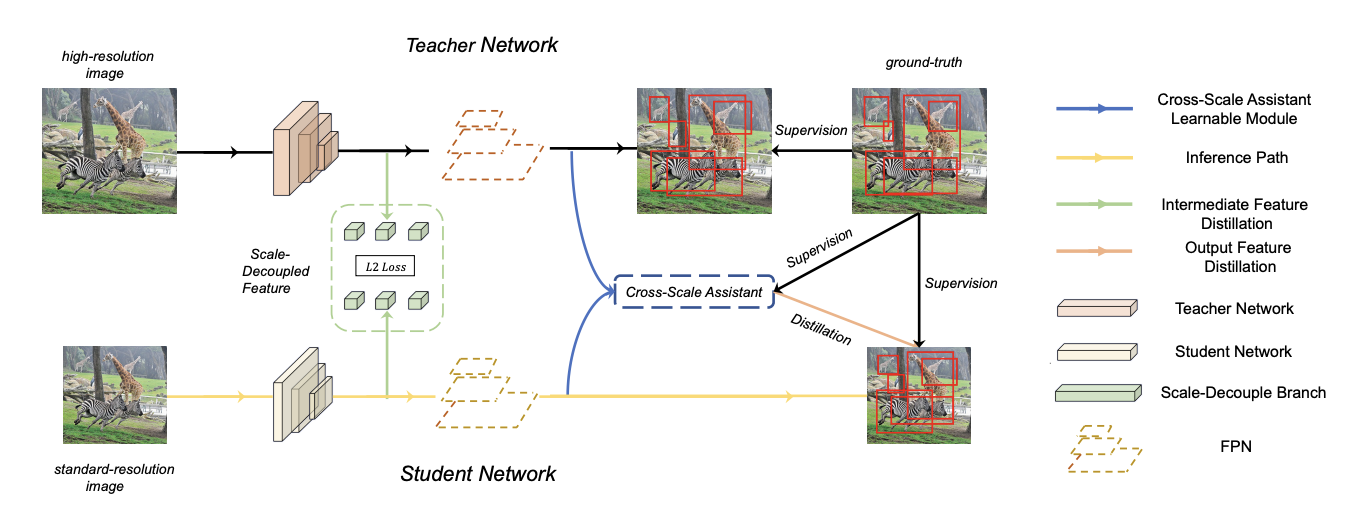
ScaleKD: Distilling Scale-Aware Knowledge in Small Object Detector, CVPR 2023
Yichen Zhu, Qiqi Zhou, Ning Liu, Zhiyuan Xu, Zhicai Ou, Xiaofeng Mou, Jian Tang
Yichen Zhu, Ning Liu, Zhiyuan Xu, Xin Liu, Weibin Meng, Louis Wang, Zhicai Ou, Jian Tang
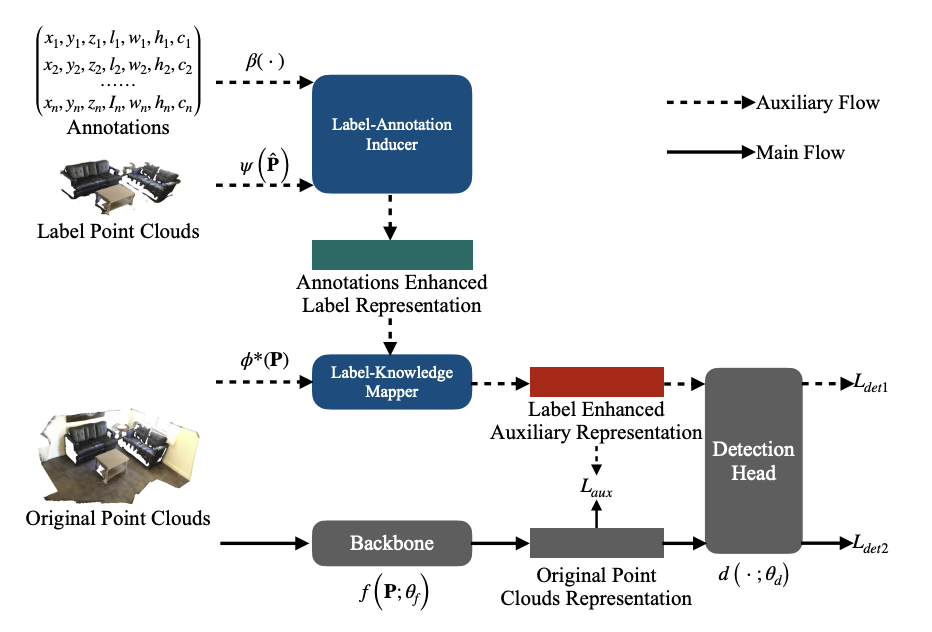
Label-guided auxiliary training improves 3d object detector, ECCV 2022
Yaomin Huang†, Xinmei Liu†, Yichen Zhu, Zhiyuan Xu, Chaomin Shen, Zhengping Che, Guixu Zhang, Yaxin Peng, Feifei Feng, Jian Tang